Inuktitut-Detect is a personal project that uses LSTMs and convolutional neural networks to classify words between english and inuktitut. The project was built to learn more about NLP and experiment with the Inuktitut Parallel Corpus.
Checkout the repo here: Inuktitut-Detect
A Brief Intro To Inuktitut
Inuktitut is the language of the Inuit, the indigenous group whose traditional lands spread across the cold and pristine area above the treeline of Labrador, Quebec, the Northwest Territories and Nunavut. Inuktitut is a diverse language with a number of dialects across different regions. There is a relatively low number of native Inuktitut speakers with just around 35000 individuals reporting it as their mother tongue.
The relatively small number of speakers, among other challenges has contributed to relatively few Inuktitut computing resources being available. Research into Inuktitut NLP is even sparser, with just a few papers being written on the topic. (Although these papers are very interesting!)
My personal interest in Inuktitut NLP comes from a number of places. In the summer of 2019 I had the wonderful opportunity of working in one of Frontier College’s indegenous summer literacy camps in the Inuit community of Inukjuak. After camp, while doing some random googling about Inuktitut I stumbled upon The Nunavut Hansard Parallel Corpus. This English-Inuktitut corpus seemed like a perfect dataset to base some rudimentary projects upon as a way of learning more about natural language processing!
The Dataset
The dataset used for this project is the The Nunavut Hansard Parallel Corpus. The corpus was created by the National Research Council of Canada and contains over 2 million lines of text. The corpus is scrapped from the proceedings of the Legislative Assembly of Nunavut. Thus a large amount of the text is on the topic of government, and even more on procedural motions, e.g. tablings, points of order, ect.
An example of the dataset is as follows:
***************
pingajuannik uqalimaarniq maligaksanit 22.
-----
Third Reading of Bills 22.
The Inuktitut and English lines are marked with * and -, making them easy to parse into a set of inuktitut and english lines.
Tokienization
The process of breaking lines into tokens is a little more nuanced and tricky than the process of breaking the dataset into lines. At the moment an extremely naive tokenization is achieved by breaking tokens up at spaces and new lines. Tokens with non alphabetic characters are filtered out. Additionally, I chose to only use unique tokens and filter out non-unique tokens. Filtering out non-unique tokens decreases the size of the dataset, which is important as this model will be trained on my laptop!
Tokens that appeared in both datasets were filtered out. Tokens appearing in both datasets were most often names (since names do not get translated) of people or places. This filtering was found to improve BCE loss by almost 0.15.
Vectorization
For the next step token was turned into a one-hot vector by mapping each character’s ascii numeric representation to the index of a one-hot vector. A sequence length of 10 was used, with padding added to the end of any shorter tokens. Finally we can train!
Neural Network Architecture
The following network architecture was designed and utilized:
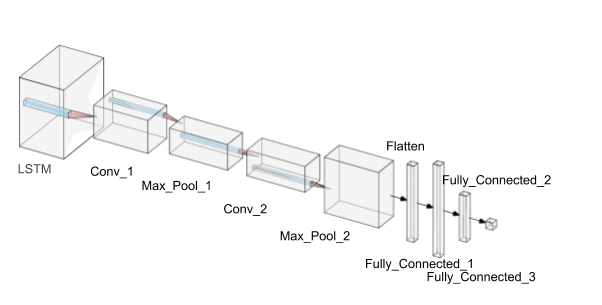
Relu activation layers are used between all network layers except the last fully connected layer and the flattening layer. A sigmoidal activation layer is used on the last fully connected layer.
Training
The ADAM optimizer is untilized to calculate gradients, along with a binary cross entropy loss function. 10000 tokiens were set aside as a testing set.
Results
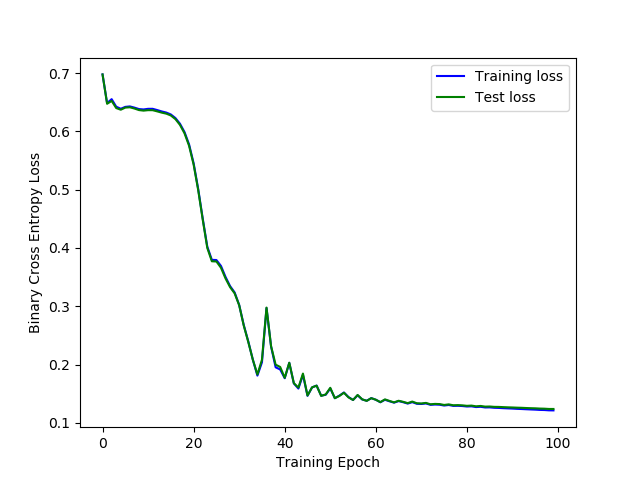
Initial results resulted in a Binary-Cross-Entropy Loss of around 0.15, with an accuracy of over 96% on the test set.
References
The UQAILAUT Project
Wikipedia:Inuktitut
NN-SVG used to create Neural Network Diagram